




























Jan 01, 1970
A todo el mundo en IA le encantan los datos sintéticos, pero nadie se pone de acuerdo sobre qué son por@marcryan
968 lecturas
A todo el mundo en IA le encantan los datos sintéticos, pero nadie se pone de acuerdo sobre qué son
Demasiado Largo; Para Leer
Los datos sintéticos son una categoría amplia con múltiples casos de uso y definiciones. En esencia, los datos sintéticos operan en dos dimensiones clave. La primera es un espectro que abarca desde completar los datos faltantes en un conjunto de datos existente hasta generar conjuntos de datos completamente nuevos. La segunda distingue entre intervenciones a nivel de datos brutos e intervenciones a nivel de información o resultados.Hable con cualquier persona que trabaje en el campo de la inteligencia artificial, el análisis o la ciencia de datos y le dirá que los datos sintéticos son el futuro. Pero si les pregunta qué quieren decir con “datos sintéticos”, obtendrá respuestas muy diferentes. Esto se debe a que los datos sintéticos no son solo una cosa, sino una categoría amplia con múltiples casos de uso y definiciones. Y esa ambigüedad hace que las conversaciones sean confusas.
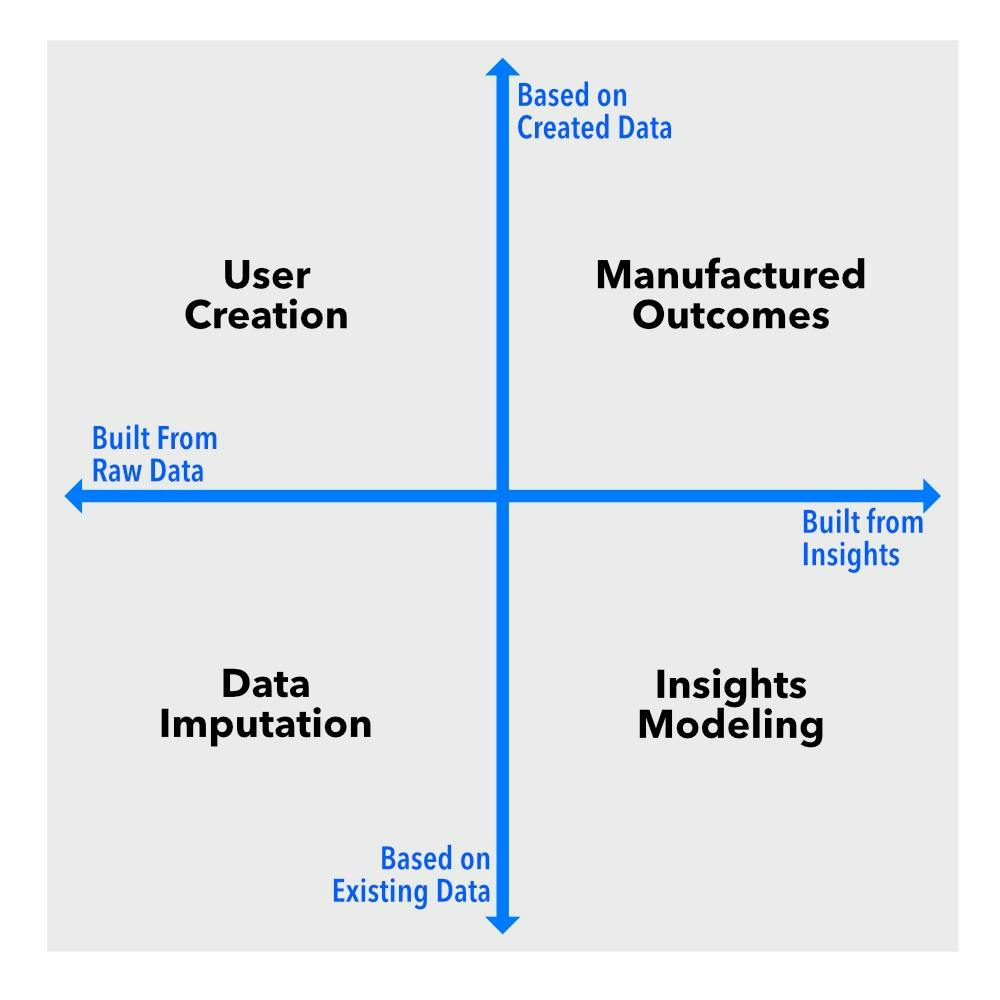
Así pues, dejemos de lado el ruido. En esencia, los datos sintéticos funcionan en dos dimensiones clave. La primera es un espectro que abarca desde completar los datos faltantes en un conjunto de datos existente hasta generar conjuntos de datos completamente nuevos. La segunda distingue entre intervenciones a nivel de datos brutos e intervenciones a nivel de información o resultados.
Imagine estas dimensiones como ejes en un gráfico. Esto crea cuatro cuadrantes, cada uno de los cuales representa un tipo diferente de datos sintéticos: imputación de datos, creación de usuarios, modelado de información y resultados manufacturados . Cada uno cumple una función distinta y, si trabaja con datos en cualquier capacidad, necesita saber la diferencia.
Imputación de datos: rellenando los espacios en blanco
Si bien algunos podrían argumentar que la imputación de datos no es verdaderamente información sintética, las técnicas de imputación modernas han evolucionado más allá de la simple sustitución de medias o medianas. Hoy, la imputación avanzada aprovecha el aprendizaje automático y los modelos de inteligencia artificial generativa, lo que hace que los valores generados sean más sofisticados y contextualmente relevantes que nunca.
La imputación de datos se encuentra en la intersección de los datos faltantes y la intervención de datos sin procesar . Esto significa que trabajamos con conjuntos de datos existentes que tienen lagunas y nuestro objetivo es generar valores plausibles para completarlos. A diferencia de otros tipos de datos sintéticos, la imputación no consiste en crear información completamente nueva, sino en hacer que los datos incompletos sean más utilizables.
Ejemplo: una empresa de investigación de mercado que realiza estudios sobre la eficacia de los medios puede tener lagunas en los datos de respuesta de su audiencia debido a la falta de respuestas de la encuesta. En lugar de descartar conjuntos de datos incompletos, las técnicas de imputación (como el modelado estadístico o el aprendizaje automático) pueden generar estimaciones realistas, lo que garantiza que los analistas puedan seguir extrayendo información significativa de los datos.
Creación de usuarios: personas falsas, información real
La creación de usuarios se encuentra entre la generación de nuevos datos y la intervención con datos sin procesar . En lugar de modificar los datos existentes, este enfoque crea perfiles y comportamientos de usuario completamente nuevos. Es particularmente útil cuando los datos de usuarios reales no están disponibles, son confidenciales o deben escalarse artificialmente.
La creación de usuarios es un elemento innovador a la hora de probar productos, mejorar la seguridad y entrenar modelos de IA.
Ejemplo: un servicio de streaming podría crear perfiles de usuarios sintéticos para probar su motor de recomendaciones sin exponer datos reales de los clientes. Las empresas de ciberseguridad hacen lo mismo para simular escenarios de ataques y entrenar sistemas de detección de fraudes.
Modelado de información: patrones sin riesgos para la privacidad
El modelado de información funciona en la intersección de los datos existentes y la intervención en el nivel de información . En lugar de manipular puntos de datos sin procesar, crea conjuntos de datos que preservan las propiedades estadísticas de los datos del mundo real sin exponer los registros reales. Esto lo hace ideal para aplicaciones que respetan la privacidad.
El modelado de información también permite a los investigadores escalar la información obtenida a partir de conjuntos de datos preexistentes, en particular cuando no es práctico recopilar datos a gran escala. Esto es habitual en la investigación de mercados, donde la recopilación de datos puede resultar engorrosa y costosa. Sin embargo, este enfoque requiere una base sólida de datos de entrenamiento del mundo real.
Ejemplo: una empresa de investigación de mercado que realiza pruebas de copia podría utilizar modelos de información para escalar su base de datos normativa. En lugar de depender únicamente de las respuestas de encuestas recopiladas, la empresa puede generar modelos de información sintéticos que extrapolan patrones de los datos normativos existentes. Esto permite a las marcas probar el rendimiento creativo frente a un conjunto de datos más amplio y predictivo sin tener que recopilar continuamente nuevas respuestas de encuestas.
Resultados fabricados: cuando los datos aún no existen
Los resultados manufacturados se encuentran en el extremo de la generación de nuevos datos y de la intervención a nivel de conocimientos . Este enfoque implica generar conjuntos de datos completamente nuevos desde cero para simular entornos o escenarios que aún no existen, pero que son esenciales para el entrenamiento, el modelado y las simulaciones de IA.
A veces, los datos que necesitas simplemente no existen, o son demasiado costosos o peligrosos de recopilar en el mundo real. Ahí es donde entran en juego los resultados manufacturados. Este proceso genera conjuntos de datos completamente nuevos, a menudo para entrenar sistemas de IA en entornos que son difíciles de replicar.
Ejemplo: las empresas de automóviles autónomos generan escenarios de carreteras sintéticos (como un peatón que cruza la calle de forma imprudente) para entrenar su IA en situaciones raras pero críticas que podrían no aparecer a menudo en imágenes de conducción del mundo real.
Riesgos y consideraciones de los datos sintéticos
Si bien los datos sintéticos brindan soluciones poderosas, no están exentos de riesgos. Cada tipo de datos sintéticos presenta sus propios desafíos que pueden afectar la calidad, la confiabilidad y el uso ético de los datos. A continuación, se presentan algunas cuestiones clave que se deben tener en cuenta:
- Propagación de sesgos: si los datos subyacentes utilizados para la imputación, el modelado de conocimientos o los resultados fabricados contienen sesgos, esos sesgos pueden reforzarse o incluso amplificarse.
- Falta de representatividad del mundo real: la creación de usuarios y la fabricación de datos pueden generar datos que parecen realistas pero no logran captar los matices del comportamiento real del usuario o las condiciones del mercado.
- Sobreajuste y falsa confianza: el modelado de información, cuando se aplica incorrectamente, puede crear datos que se alinean demasiado con el conjunto de entrenamiento, lo que lleva a conclusiones engañosas.
- Preocupaciones regulatorias y éticas: Las leyes de privacidad como GDPR y CCPA aún se aplican a los datos sintéticos si pueden modificarse mediante ingeniería inversa para identificar a personas reales.
Preguntas clave que se deben plantear al evaluar datos sintéticos
Para garantizar que los datos sintéticos cumplan con los estándares de calidad, considere estas preguntas:
- ¿Cuál es la fuente de los datos originales? Comprender la base de los datos sintéticos ayuda a evaluar posibles sesgos y limitaciones.
- ¿Cómo se generaron los datos sintéticos? Diferentes métodos (aprendizaje automático, modelos estadísticos o sistemas basados en reglas) afectan la confiabilidad de los datos sintéticos.
- ¿Los datos sintéticos mantienen la integridad estadística de los datos del mundo real? Asegúrese de que los datos generados se comporten de manera similar a los datos reales sin simplemente duplicarlos.
- ¿Se pueden auditar o validar los datos sintéticos? Los datos sintéticos fiables deben contar con mecanismos de validación.
- ¿Cumple con las normas éticas y regulatorias? El hecho de que los datos sean sintéticos no significa que estén exentos de las normas de privacidad.
- ¿Existe un proceso para actualizar los modelos de datos subyacentes? Los datos sintéticos son tan buenos como los datos del mundo real en los que se basan. Garantizar un proceso para actualizar continuamente el conjunto de datos de base evita que los modelos queden obsoletos y no se ajusten a las tendencias actuales.
Envolviéndolo
Los datos sintéticos son un término amplio y, si trabaja en el campo de la inteligencia artificial, el análisis o cualquier otro campo basado en datos, debe tener claro con qué tipo de datos está tratando. ¿Está completando los datos faltantes (imputación), creando usuarios de prueba (creación de usuarios), generando patrones anónimos (modelado de información) o construyendo conjuntos de datos completamente nuevos desde cero (resultados fabricados)?
Cada uno de estos factores desempeña un papel diferente en la forma en que utilizamos y protegemos los datos, y comprenderlos es fundamental para tomar decisiones informadas en el mundo de la IA y la ciencia de datos, que evoluciona rápidamente. Así que la próxima vez que alguien mencione el término “datos sintéticos”, pregúntele: ¿de qué tipo?
L O A D I N G
. . . comments & more!
. . . comments & more!



