





New Story
What Makes a Scene Important? This AI Knows





Too Long; Didn't Read
This paper introduces a new dataset of 100 movie scripts with human-annotated salient scenes and proposes a two-stage model, SELECT & SUMM, which first identifies key scenes and then generates summaries using only those. The approach outperforms prior models in accuracy and efficiency, making movie script summarization more scalable and informative.People Mentioned


Companies Mentioned

Coin Mentioned






Authors:
(1) Rohit Saxena, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburg;
(2) RFrank Keller, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburg.
Table of Links
6. Automatic QA-based Evaluation
Metrics like ROUGE (lexically based) and BERTScore (embedding based) are good for comparing the topic similarity between the reference and generated summaries, but fail to compare content-based factual consistency. To further evaluate the performance of our model, we used QAEval (Deutsch et al., 2021), a question-answering-based evaluation that generates question-answer pairs using the reference summaries. It then uses the modelgenerated summaries (candidates) to answer these questions, thereby measuring information overlap. It reports two standard answer verification methods used by SQuAD, F1 and exact match (EM) (Rajpurkar et al., 2016), averaged over all questions for all model-generated summaries.
Before the final evaluation, we filtered the generated questions using a question filtering method similar to Fabbri et al. (2022), which is useful for removing spurious questions/answers (for example answers consisting of personal pronouns and wh-pronouns). Table 6 shows results for QAEval on summaries generated by models using full text input, the two-stage heuristic approach (Pu et al., 2022), and Select and Summarize (our model). We find that Select and Summarize performs better in answering factual questions, with a mean F1 of 29.42 and a mean exact match of 20.05%. Our model shows a clear improvement over using full movie scripts or a two-stage heuristic approach.

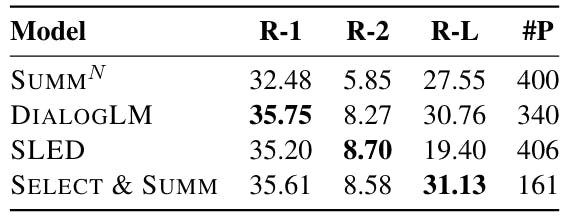
7. Zero-Shot on SummScreen-FD
We further investigate the performance of the scene saliency classifier on SummScreenFD (Chen et al., 2022) as used in SCROLLS benchmark (Shaham et al., 2022). SummScreenFD consists of transcripts of TV show episodes with human-written recaps. We performed a zero-shot classification of the salient scenes on the SummScreenFD and used only salient scenes to fine-tune LED for summarization. We compare the results with state-of-the-art methods on the dataset and report ROUGE scores. We observe that our model achieves comparable results to the state of the art on the SummScreenFD dataset as shown in Table 7, but with fewer parameters (Ivgi et al., 2023; Zhong et al., 2022).
8. Discussion and Conclusion
In this paper, we introduced a dataset of 100 movies in which movie plot summaries are manually aligned with scenes in the corresponding movie script. Our dataset can be used to evaluate content selection strategies and extractive summarization for movie scripts. Using this dataset, we proposed a scene saliency classification model for the automatic identification of salient scenes in a movie script and introduced an abstractive summarization model that only uses the salient scenes to generate the movie summary. Our experiments showed that the proposed model achieves a significant improvement over the previous state of the art on the Scriptbase corpus for movie script summarization and performs comparable to the state of the art on the SummScreenFD dataset using zero-shot salient scene detection.
Our work demonstrates that the output of a summarization model can improve when content selection is performed (by using only the salient scenes). A good content selection strategy can in principle reduce the input size without compromising the quality of the generated output. As a result of the smaller input size, the computational and memory requirements of the underlying large language model can be significantly reduced.
Limitations
Limitations of this work include that we defined the saliency of a scene as recall in user-written summaries. However, there are many aspects that can make a scene salient, including the presence of an important character or event in the scene, or just the fact that the scene is visually stunning. These factors can be explored in future work. Also, we discovered that many of the movie scripts in the Scriptbase corpus are not the final production scripts, which means they are different from the final movie as it was released. This imposes a limit on the quality of the summary that can be generated from a script. Our current model works in a pipeline of salient scene classification and then uses these scenes to summarize the movie. This means that it can propagate salience classification errors into the summarization step. Human evaluation of summaries generated from long-form text is challenging, as it requires human evaluators to read very long texts such as movie scripts. Therefore, future work is required to evaluate automatically generated movie summaries.
Ethics Statement
Large Language Models: This paper uses pretrained large language models, which have been shown to be subject to a variety of biases, to occasionally generate toxic language, and to hallucinate content. Therefore, the summaries generated by our approach should not be released without automatic filtering or manual checking.
Experimental Participants: The departmental ethics panel judged our human annotation study to be exempt from ethical approval, as all participants were employees of the University of Edinburgh, and as such were protected by employment law. Nevertheless, annotators were given a participant information sheet before they started work. They were also informed about the age rating of each movie script, based on which they could decide whether they want to annotate this script or not. Participants were paid at the standard hourly rate for tutors and demonstrators at the university.
Acknowledgements
This work was supported in part by the UKRI Centre for Doctoral Training in Natural Language Processing, funded by UK Research and Innovation (grant EP/S022481/1), Huawei, and the School of Informatics at the University of Edinburgh. We would like to thank the anonymous reviewers for their helpful feedback.
References
Divyansh Agarwal, Alexander R. Fabbri, Simeng Han, Wojciech Kryscinski, Faisal Ladhak, Bryan Li, Kathleen McKeown, Dragomir Radev, Tianyi Zhang, and Sam Wiseman. 2022. CREATIVESUMM: Shared task on automatic summarization for creative writing. In Proceedings of The Workshop on Automatic Summarization for Creative Writing, pages 67–73, Gyeongju, Republic of Korea. Association for Computational Linguistics.
Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The long-document transformer. arXiv:2004.05150.
Amanda Bertsch, Uri Alon, Graham Neubig, and Matthew Gormley. 2023. Unlimiformer: Long-range transformers with unlimited length input. In Advances in Neural Information Processing Systems, volume 36, pages 35522–35543. Curran Associates, Inc.
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
Mingda Chen, Zewei Chu, Sam Wiseman, and Kevin Gimpel. 2022. SummScreen: A dataset for abstractive screenplay summarization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8602–8615, Dublin, Ireland. Association for Computational Linguistics.
Yen-Chun Chen and Mohit Bansal. 2018. Fast abstractive summarization with reinforce-selected sentence rewriting. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 675–686, Melbourne, Australia. Association for Computational Linguistics.
Jianpeng Cheng and Mirella Lapata. 2016. Neural summarization by extracting sentences and words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 484–494, Berlin, Germany. Association for Computational Linguistics.
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416.
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. 2018. A discourse-aware attention model for abstractive summarization of long documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 615–621, New Orleans, Louisiana. Association for Computational Linguistics.
Daniel Deutsch, Tania Bedrax-Weiss, and Dan Roth. 2021. Towards question-answering as an automatic metric for evaluating the content quality of a summary. Transactions of the Association for Computational Linguistics, 9:774–789.
Zi-Yi Dou, Pengfei Liu, Hiroaki Hayashi, Zhengbao Jiang, and Graham Neubig. 2021. GSum: A general framework for guided neural abstractive summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4830–4842, Online. Association for Computational Linguistics.
Ori Ernst, Ori Shapira, Ramakanth Pasunuru, Michael Lepioshkin, Jacob Goldberger, Mohit Bansal, and Ido Dagan. 2021. Summary-source proposition-level alignment: Task, datasets and supervised baseline. In Proceedings of the 25th Conference on Computational Natural Language Learning, pages 310–322. Association for Computational Linguistics.
Alexander Fabbri, Chien-Sheng Wu, Wenhao Liu, and Caiming Xiong. 2022. QAFactEval: Improved QAbased factual consistency evaluation for summarization. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2587–2601, Seattle, United States. Association for Computational Linguistics.
Sebastian Gehrmann, Yuntian Deng, and Alexander Rush. 2018. Bottom-up abstractive summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4098–4109, Brussels, Belgium. Association for Computational Linguistics.
Philip John Gorinski and Mirella Lapata. 2015. Movie script summarization as graph-based scene extraction. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1066–1076, Denver, Colorado. Association for Computational Linguistics.
Philip John Gorinski and Mirella Lapata. 2018. What’s this movie about? a joint neural network architecture for movie content analysis. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1770–1781, New Orleans, Louisiana. Association for Computational Linguistics.
Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. 2021. Efficient attentions for long document summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1419–1436, Online. Association for Computational Linguistics.
Maor Ivgi, Uri Shaham, and Jonathan Berant. 2023. Efficient Long-Text Understanding with Short-Text Models. Transactions of the Association for Computational Linguistics, 11:284–299.
Wojciech Kryscinski, Nazneen Rajani, Divyansh Agarwal, Caiming Xiong, and Dragomir Radev. 2022. BOOKSUM: A collection of datasets for long-form narrative summarization. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 6536–6558, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Faisal Ladhak, Bryan Li, Yaser Al-Onaizan, and Kathleen McKeown. 2020. Exploring content selection in summarization of novel chapters. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5043–5054, Online. Association for Computational Linguistics.
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics, 12:157–173.
Shuaiqi Liu, Jiannong Cao, Ruosong Yang, and Zhiyuan Wen. 2022. Long text and multi-table summarization: Dataset and method. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 1995–2010, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Yang Liu and Mirella Lapata. 2019. Text summarization with pretrained encoders. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3730–3740, Hong Kong, China. Association for Computational Linguistics.
Potsawee Manakul and Mark Gales. 2021. Long-span summarization via local attention and content selection. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 6026–6041, Online. Association for Computational Linguistics.
Rada Mihalcea and Paul Tarau. 2004. TextRank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, pages 404–411, Barcelona, Spain. Association for Computational Linguistics.
Paramita Mirza, Mostafa Abouhamra, and Gerhard Weikum. 2021. AligNarr: Aligning narratives on movies. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 427–433, Online. Association for Computational Linguistics.
Pinelopi Papalampidi, Frank Keller, Lea Frermann, and Mirella Lapata. 2020. Screenplay summarization using latent narrative structure. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 1920–1933, Online. Association for Computational Linguistics.
Pinelopi Papalampidi, Frank Keller, and Mirella Lapata. 2019. Movie plot analysis via turning point identification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 1707–1717, Hong Kong, China. Association for Computational Linguistics.
Pinelopi Papalampidi, Frank Keller, and Mirella Lapata. 2021. Movie summarization via sparse graph construction. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 13631– 13639.
Jason Phang, Yao Zhao, and Peter Liu. 2023. Investigating efficiently extending transformers for long input summarization. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3946–3961, Singapore. Association for Computational Linguistics.
Dongqi Pu, Xudong Hong, Pin-Jie Lin, Ernie Chang, and Vera Demberg. 2022. Two-stage movie script summarization: An efficient method for low-resource long document summarization. In Proceedings of The Workshop on Automatic Summarization for Creative Writing, pages 57–66, Gyeongju, Republic of Korea. Association for Computational Linguistics.
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392, Austin, Texas. Association for Computational Linguistics.
Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. 2023. ZeroSCROLLS: A zero-shot benchmark for long text understanding. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7977–7989, Singapore. Association for Computational Linguistics.
Uri Shaham, Elad Segal, Maor Ivgi, Avia Efrat, Ori Yoran, Adi Haviv, Ankit Gupta, Wenhan Xiong, Mor Geva, Jonathan Berant, and Omer Levy. 2022. SCROLLS: Standardized CompaRison over long language sequences. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 12007–12021, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
Fei Wang, Kaiqiang Song, Hongming Zhang, Lifeng Jin, Sangwoo Cho, Wenlin Yao, Xiaoyang Wang, Muhao Chen, and Dong Yu. 2022. Salience allocation as guidance for abstractive summarization. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 6094–6106, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. 2022. Finetuned language models are zero-shot learners. In International Conference on Learning Representations.
Yongjian You, Weijia Jia, Tianyi Liu, and Wenmian Yang. 2019. Improving abstractive document summarization with salient information modeling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2132– 2141, Florence, Italy. Association for Computational Linguistics.
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santiago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, and Amr Ahmed. 2020. Big bird: Transformers for longer sequences. In Advances in Neural Information Processing Systems, volume 33, pages 17283–17297. Curran Associates, Inc.
Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu. 2020a. PEGASUS: Pre-training with extracted gap-sentences for abstractive summarization. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 11328–11339. PMLR.
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020b. BERTScore: evaluating text generation with BERT. In International Conference on Learning Representations.
Yusen Zhang, Ansong Ni, Ziming Mao, Chen Henry Wu, Chenguang Zhu, Budhaditya Deb, Ahmed Awadallah, Dragomir Radev, and Rui Zhang. 2022. Summn: A multi-stage summarization framework for long input dialogues and documents. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1592– 1604, Dublin, Ireland. Association for Computational Linguistics.
Hao Zheng and Mirella Lapata. 2019. Sentence centrality revisited for unsupervised summarization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 6236– 6247, Florence, Italy. Association for Computational Linguistics.
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. In Advances in Neural Information Processing Systems, volume 36, pages 46595–46623. Curran Associates, Inc.
Ming Zhong, Yang Liu, Yichong Xu, Chenguang Zhu, and Michael Zeng. 2022. Dialoglm: Pre-trained model for long dialogue understanding and summarization. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 11765– 11773.
Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, and Dragomir Radev. 2021. QMSum: A new benchmark for querybased multi-domain meeting summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5905–5921, Online. Association for Computational Linguistics.
Chenguang Zhu, Yang Liu, Jie Mei, and Michael Zeng. 2021a. MediaSum: A large-scale media interview dataset for dialogue summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5927–5934, Online. Association for Computational Linguistics.
Chenguang Zhu, Ziyi Yang, Robert Gmyr, Michael Zeng, and Xuedong Huang. 2021b. Leveraging lead bias for zero-shot abstractive news summarization. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’21, page 1462–1471, New York, NY, USA. Association for Computing Machinery.
This paper is available on arxiv under CC BY 4.0 DEED license.

L O A D I N G
. . . comments & more!
. . . comments & more!












